Benchmarking OCR for Dental Components
PaddleOCR and VLM results on faint text etched on curved orthodontic appliances, plus what it takes to deploy robust OCR on the line.

Research: OCR Benchmark on Dental Engraving
Some industrial OCR datasets are unforgiving. Teeth alignment trays carry shallow engravings across glossy, curved plastic, so characters are revealed only through subtle shadows. Reflection, non-uniform lighting, and atypical fonts push traditional OCR beyond its comfort zone. We collected two representative lines—Henry and K-Line—to measure how vision-language models (VLMs) and PaddleOCR variants cope with this scenario.
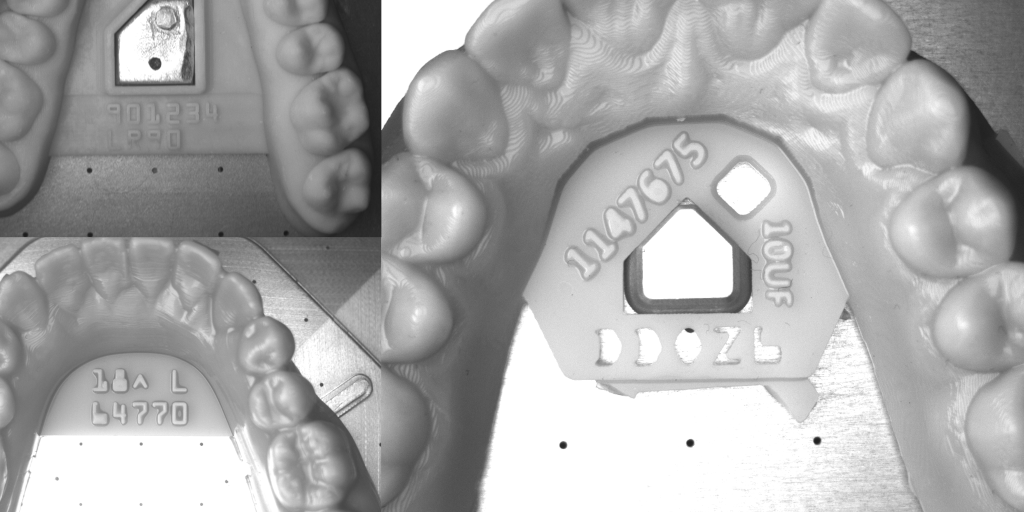
Metric and Setup
We grade everything with Exact Match (EM) on the full identifier. One wrong character gives everything as incorrect.
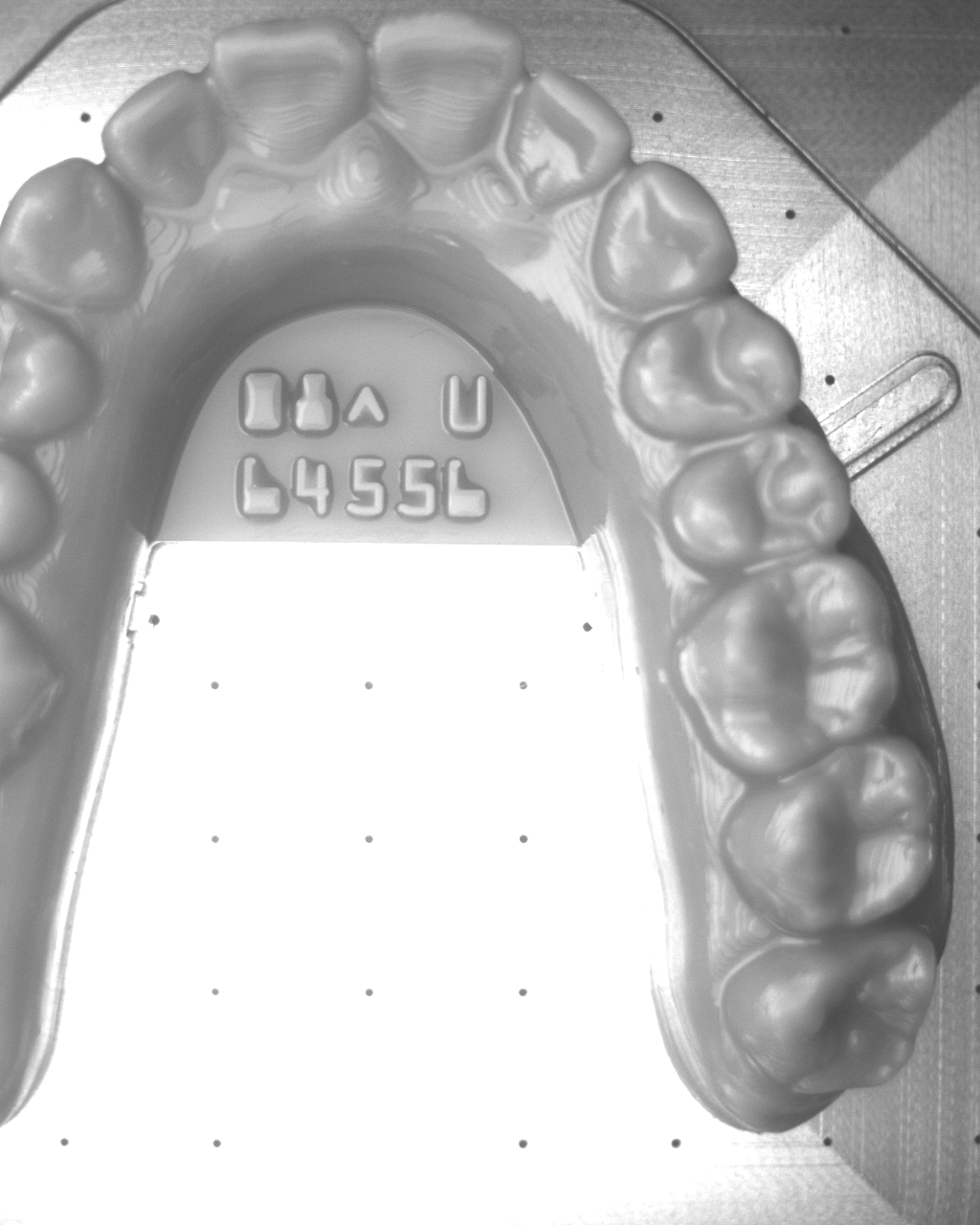
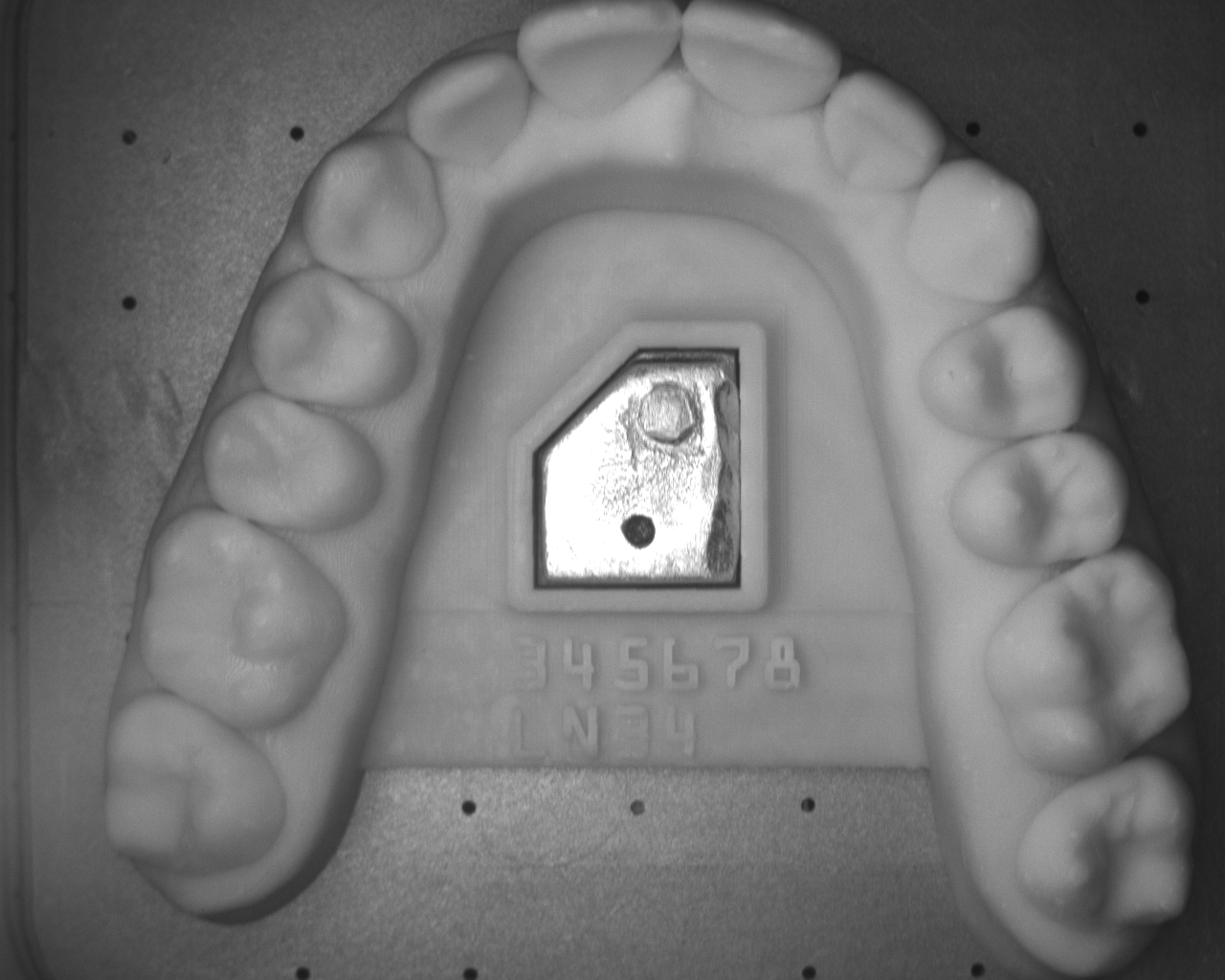
How VLMs Behave on Engraved Text
VLMs promise flexibility without custom training, but their decoding policies matter. We tested publicly available checkpoints with short prompts asking for raw text output. Adding lightweight constraints about the target format (numbers, caret symbol, optional trial letter) substantially improves results.
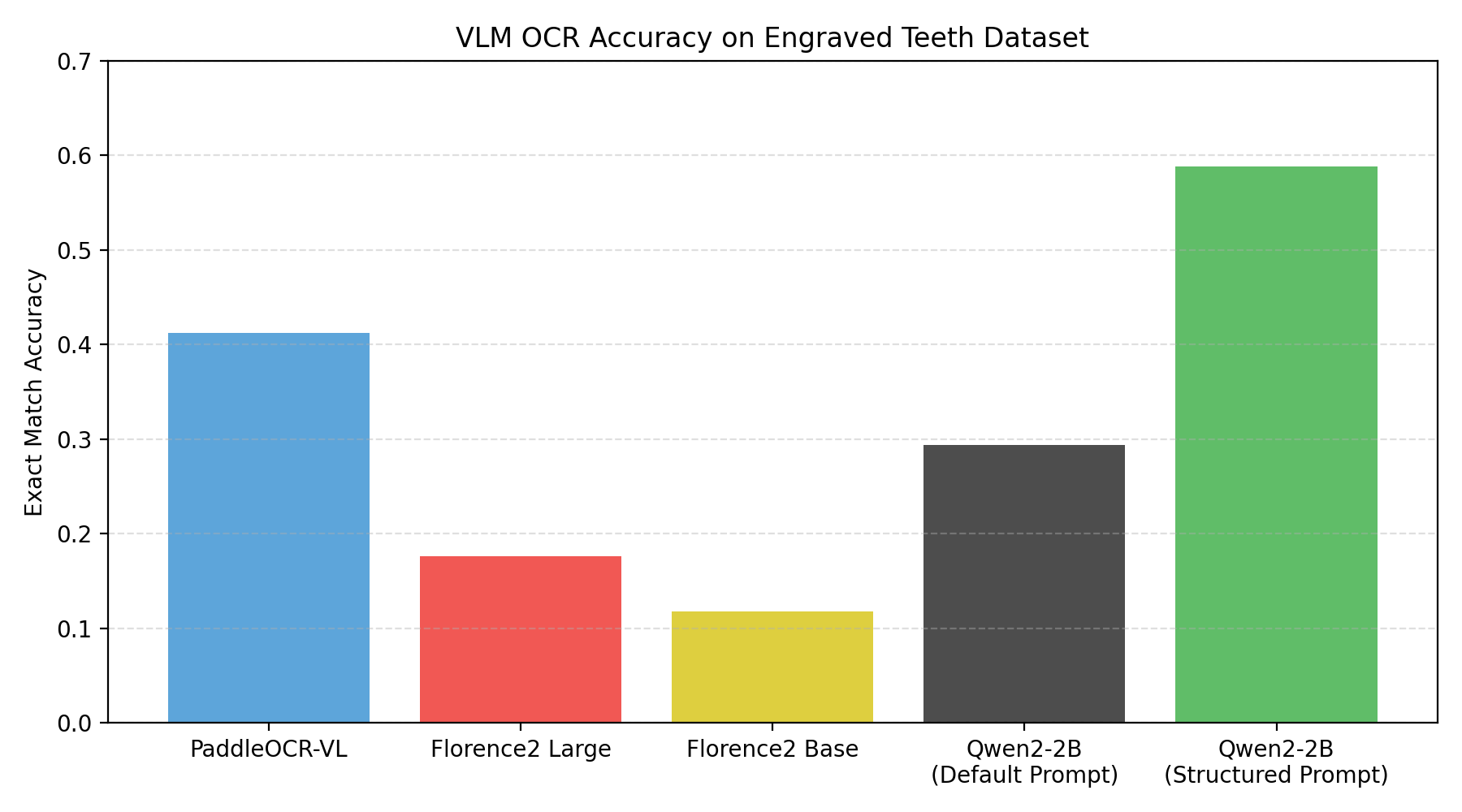
- Structured prompts help: Qwen2-2B jumped from 0.294 EM to 0.588 when we forced it to emit only the expected pattern.
- PaddleOCR-VL still leads on this niche dataset with 0.412 EM, but it misreads specific characters that have unexpected fonts.
- Florence2 underperformed (<0.18 EM) with this specific dataset.
Overall, zero-shot VLMs remain unreliable for compliance strings unless the hardware allows for multiple attempts with majority voting.
PaddleOCR: Great When Trained, Brittle When Not
PaddleOCR Mobile and Server models were evaluated both as off-the-shelf checkpoints and after fine-tuning solely on Henry imagery. We then measured their EM on both lines to understand generalization.
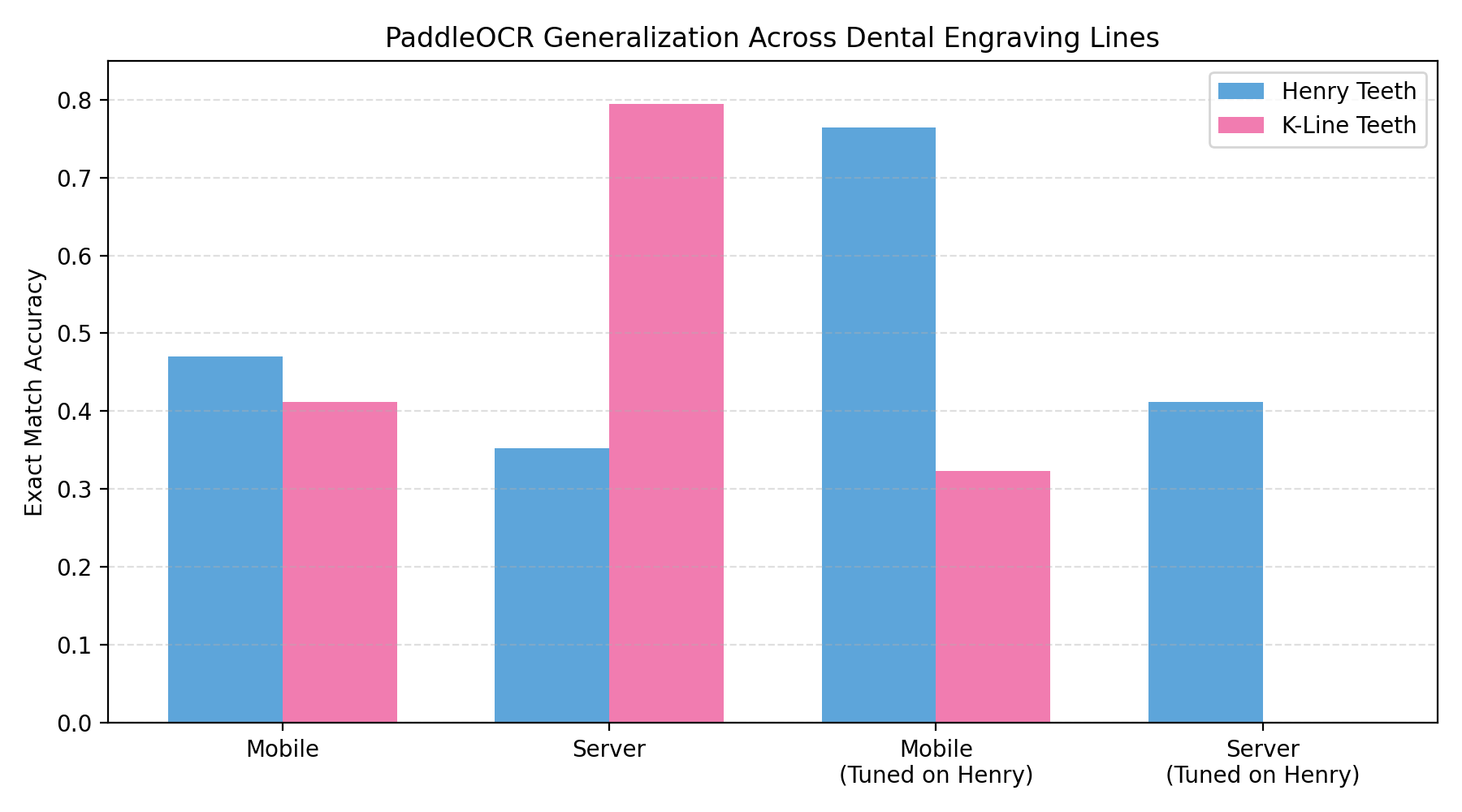
- Henry line: tuning on in-line data lifts Mobile EM to 0.7647, which is production-ready once paired with rejection logic.
- K-Line line: the same tuned model collapses to 0.3235 EM, proving it memorized Henry-specific lighting artifacts instead of engravings.
- Server checkpoint: excels on K-Line when left generic (0.7941 EM), but performance drops to 0 after being overfitted on Henry captures.
Such datasets expose how hard it is to generalize; a model trained on one engraver’s format cannot be trusted on a different fixture without re-labeling. Interestingly, the smaller Mobile backbone tends to benefit more from targeted tuning because it needs fewer samples to fit the distribution, partially explaining its larger boost on Henry compared with the heavier Server model.
Key Observations
- Prompt constraints are a cheap win for VLMs, but they can’t surpass OCR models tuned on the right data.
- Generalization is the real bottleneck: switch line formats without retraining and EM can swing from 0.76 to 0.32.
- Model size influences data appetite: compact models adapt faster (good for per-line tuning) while larger ones remain more stable when left generic.
With these insights, Rosepetal AI keeps a hybrid stack ready: VLMs bootstrap labels and monitor drift, while PaddleOCR variants are fine-tuned per line to guarantee that engraved IDs stay traceable.