Model Conversion Times for Edge AI Deployment
Benchmarking PyTorch YOLOv8, ONNX, TensorRT FP32/FP16/INT8, and TorchScript runtimes with accuracy, latency, and throughput measurements.

Optimizing an inspection model is a lot like selecting the right tool on a production line: the model may be the same, but its container (runtime) decides how quickly it reacts. To make that choice simpler, we converted our YOLOv8-based quality-control model into ONNX, TensorRT (multiple precisions), and TorchScript, then compared accuracy and speed side by side. Each runtime was tested with the same validation set. We also rechecked precision and recall after every conversion so the accuracy comparison stayed fair.
Accuracy Snapshot
| Runtime | Precision | Recall | mAP50 | mAP50-95 |
|---|---|---|---|---|
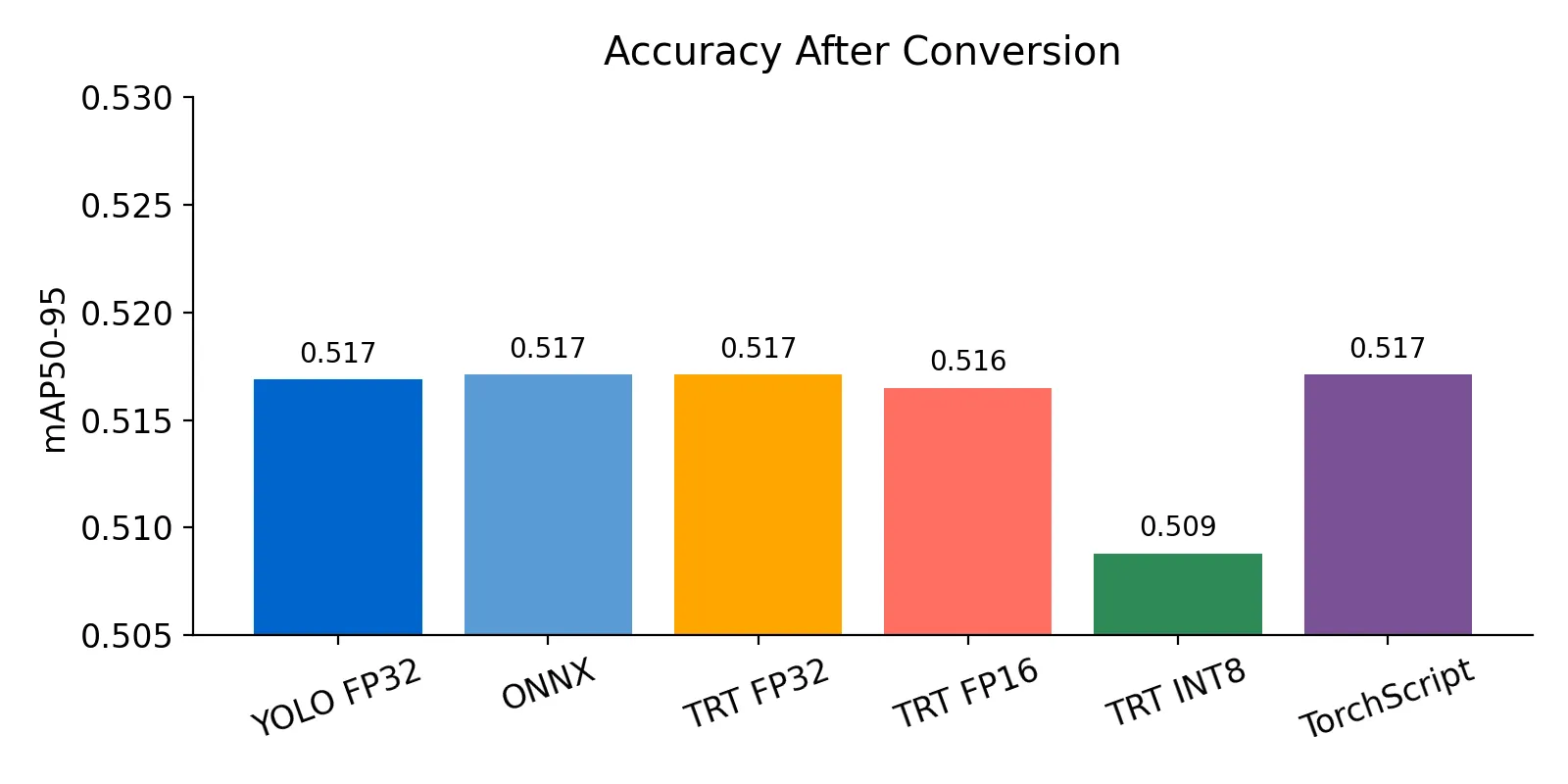
| PyTorch YOLOv8 FP32 | 0.933 | 0.882 | 0.916 | 0.517 |
| ONNX (static input) | 0.934 | 0.882 | 0.918 | 0.517 |
| TensorRT FP32 (dynamic profile) | 0.934 | 0.882 | 0.918 | 0.517 |
| TensorRT FP16 | 0.934 | 0.882 | 0.919 | 0.516 |
| TensorRT INT8 | 0.919 | 0.882 | 0.931 | 0.509 |
| TorchScript | 0.934 | 0.882 | 0.918 | 0.517 |
The chart below shows how little the accuracy moved even after the most aggressive conversion. In short: everything stayed within striking distance of the PyTorch baseline, and the INT8 version actually gave us a tiny boost on mAP50.
Speed & Throughput
The table and charts turn the stopwatch data into an easier view. Values are in milliseconds for single predictions and seconds for the time it takes to finish 250 frames.
| Runtime | 1x1 Latency (ms) | 1x2 Latency (ms) | 2x1 Latency (ms) | 250 Frames @1x1 (s) |
|---|---|---|---|---|
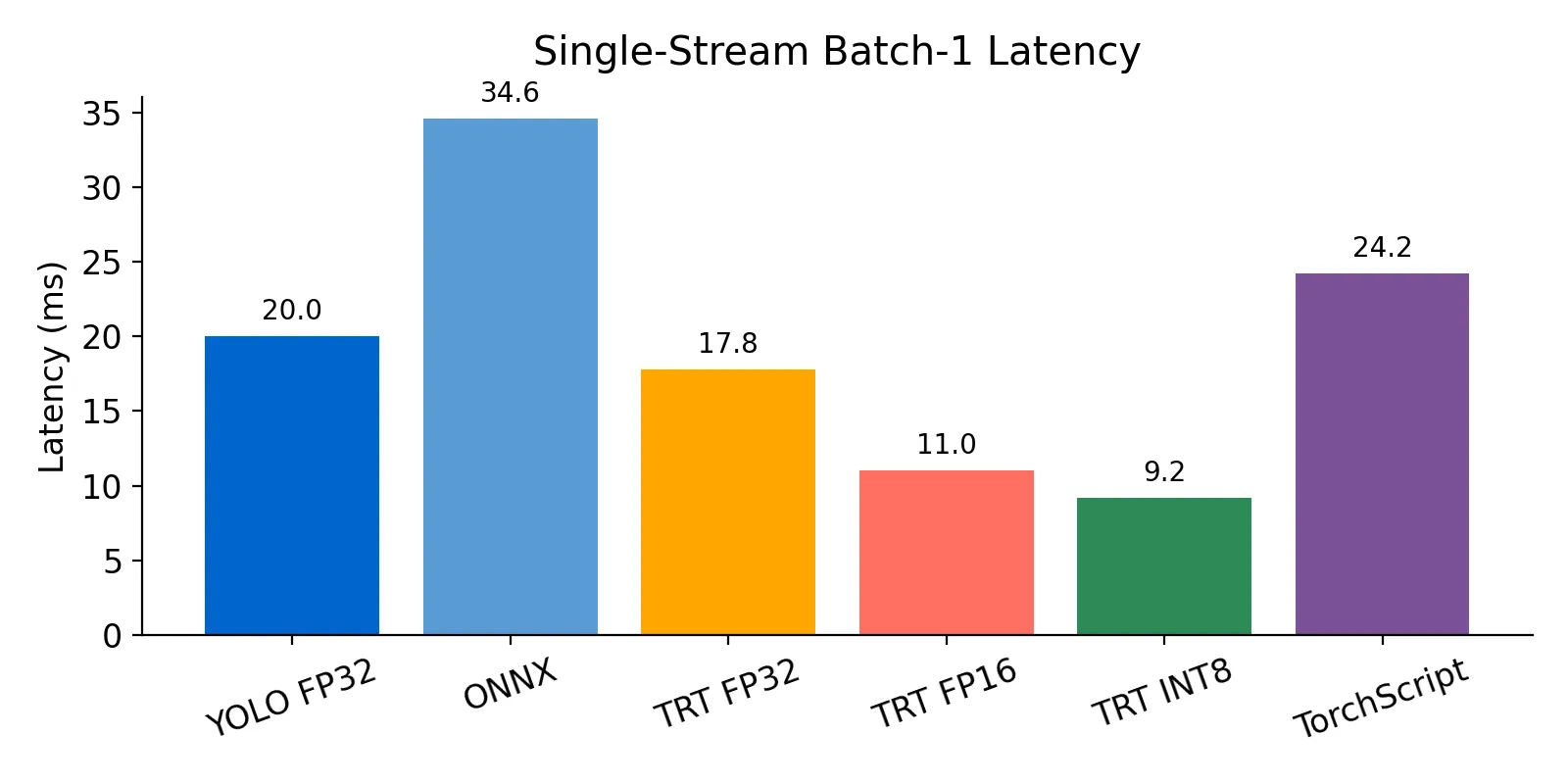
| PyTorch YOLOv8 FP32 | 20.0 | 21.0 | 38.0 | 5.00 |
| ONNX (static input) | 34.6 | 33.6 | 67.0 | 8.64 |
| TensorRT FP32 (dynamic) | 17.8 | 20.2 | 35.6 | 4.44 |
| TensorRT FP32 (ND batch-1) | 21.6 | --- | 43.1 | 5.39 |
| TensorRT FP16 | 11.0 | 10.1 | 18.7 | 2.75 |
| TensorRT INT8 | 9.2 | 8.5 | 15.4 | 2.29 |
| TorchScript | 24.2 | 24.9 | 49.0 | 6.05 |
- The best TensorRT FP32 setup lowered single-stream latency to 17.8 ms, a quick win without touching precision.
- FP16 (the “half” version) almost halved latency to 11 ms and needed no retraining.
- INT8 required a calibration pass but ran at 9.2 ms and finished 250 frames in 2.29 s.
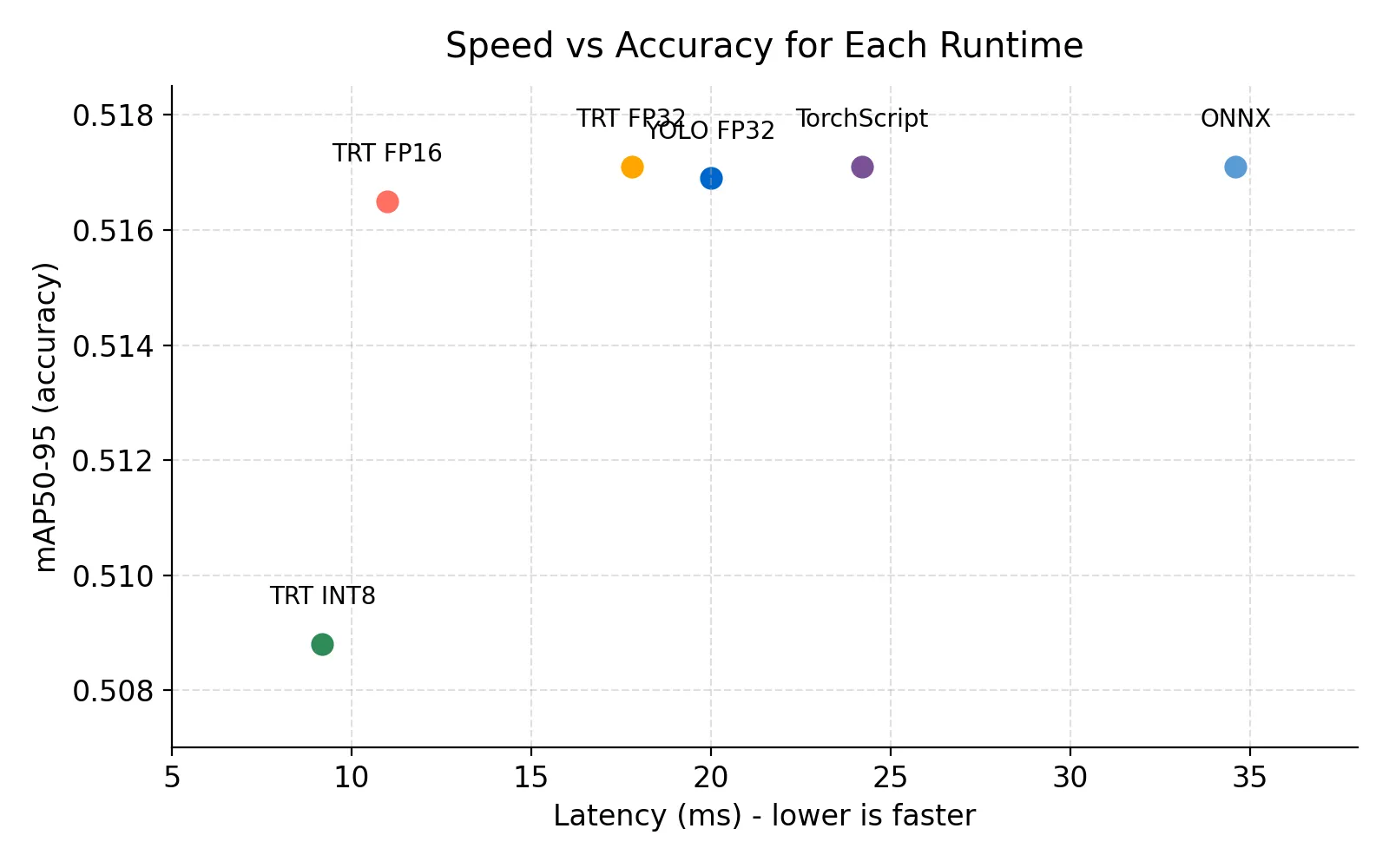
To visualize the trade-off between raw speed and accuracy, we plotted each runtime on the chart below.
TensorRT Profile Tuning
To squeeze out a bit more speed we exported two FP32 TensorRT engines:
- ND batch-1 profile (
nd_b1): tuned strictly for batch-1 inputs. - Dynamic profile for batch-1 / batch-2 (
d_b1 / nd_b2): handles small bursts (batch-2) while staying fast on batch-1.
The dynamic profile responded faster when we spun up a second stream (20.2 ms vs 43.1 ms) and still beat the PyTorch baseline. That tuning step alone recovered roughly one millisecond per frame without sacrificing accuracy.
Precision-Driven Speedups
- FP16 (
half): Halved inference time to 11 ms with a single command. No retraining, just export-and-go. - INT8 (
int): Adds a short calibration step but rewards it with 9.2 ms single-stream latency and 3.84 s for 250 frames when running two pipelines.
Takeaways
- ONNX is a useful interchange format, but treat it as a temporary stop; it matched accuracy yet ran 70% slower than PyTorch.
- TensorRT FP32 with a dynamic profile is the easiest speed boost: no accuracy loss and a measurable latency cut.
- FP16 strikes the best balance for most factories, giving a 2x speedup with identical detection quality.
- INT8 is ideal for high-speed lines where every millisecond counts; it cleared our sample almost twice as fast as the baseline.